NEST Graph #
This page contains the following content:
Overview #
The following measures exist for computing similarities between NEST graphs:
graph TD; NESTGraphMeasures[NEST Graph Measures] --> NESTGraphItemMeasures[Graph Item Measure]; NESTGraphMeasures --> NESTSequentialWorkflowMeasures[Sequence Similarity Based Measures]; NESTGraphMeasures --> NESTWorkflowMeasures[A* Measures]; NESTSequentialWorkflowMeasures --> SWA[Smith Waterman Algorithm]; NESTSequentialWorkflowMeasures --> DTW[Dynamic Time Warping]; NESTWorkflowMeasures --> AI[A*I]; NESTWorkflowMeasures --> AII[A*II]; NESTWorkflowMeasures --> AIII[A*III];
The following table shows to which data classes these similarity measures can be applied. (X indicates that the measure is applicable and - indicates that it cannot be applied.)
| Name of similarity measure (underlying algorithm) | NESTGraph | NESTSequentialWorkflow | NESTWorkflow |
|---|---|---|---|
| GraphSWA (Smith Waterman Algorithm) | - | X | - |
| GraphDTW (Dynamic Time Warping) | - | X | - |
| GraphAStarOne (A* Search) | X | X | X |
| GraphAStarTwo (A* Search) | X | X | X |
| GraphAStarThree (A* Search) | X | X | X |
If a measure is allowed for different data classes, it can be applied with one object of each data class. For example, the similarity of a NESTSequentialWorkflowObject to a NESTWorkflow can be calculated using A*I. The SWA and DTW measures can only be applied to valid NESTSequentialWorkflows. It is possible that a NESTGraph or NESTWorkflow may also fulfill the conditions of a sequential workflow, so that the similarity calculation could also be performed using these measures. However, this requires that the objects are converted into a NESTSequentialWorkflow object first.
NEST Graph Item #
| Parameter | Type/Range | Default Value | Description |
|---|---|---|---|
| requireEqualDataClass | Boolean | true | Controls, if both elements must be of the same data class. |
The nest graph item similarity measure computes the similarity between two nest graph item objects based on their semantic descriptors. For these computations, local similarity measures are called. Configurable by a parameter requireEqualDataClass, it is controlled, if both elements must be of the same data class to be compared or not. Per default, this value is true. In this case, if both elements are of different data classes, the similarity is 0.0.
In the file sim.xml this measure can be defined as follows:
<NESTGraphItem name="NESTGraphItem" class="NESTGraphElement" requireEqualDataClass="false"/>
At runtime, the measure can be defined as follows:
SMNESTGraphItem smNESTGraphItem = (SMNESTGraphItem) simVal.getSimilarityModel().createSimilarityMeasure(
SMNESTGraphItem.NAME,
ModelFactory.getDefaultModel().getNESTGraphItemClass()
);
smNESTGraphItem.setRequireEqualDataClass(false);
simVal.getSimilarityModel().addSimilarityMeasure(smNESTGraphItem, SMNESTGraphItem.NAME);
Sequence Similarity Based Measures #
Sequential graphs can be regarded as time series. Therefore, two algorithms (Smith Waterman Algorithm (SWA) and Dynamic Time Warping (DTW)) based on sequence matching have been adapted for comparing two NESTSequentialWorkflowObjects. A comprehensive overview of the algorithms themselves is presented in context of the Collection similarity measures. Both, the Smith Waterman Algorithm (SWA)-based and Dynamic Time Warping (DTW)-based workflow similarity measures can solely be applied to NESTSequentialWorkflow instances (see here).
Characteristics #
Since both SWA and DTW are time series based similarity measures, they can be applied to all ordered lists of arbitrary data (as long as individual items are comparable). When applied to de facto instances, specific characteristics of NESTSequentialWorkflow are also taken into account by the measure. Specifically, local (task) similarities that are required to construct the scoring matrix, now also take dataflow similarity into account. For this purpose - on the local level (when comparing two task nodes - incoming and outgoing data-flow is compared respectively. This is done by utilization of the CollectionMapping measure:
\(sim_{loc}(q_i,c_j) = \frac{l_t * sim_N(q_i,c_j) + l_i * sim_{dataflow}(in_{q_i},in_{c_j}) + l_o * sim_{dataflow}(out_{q_i},out_{c_j})}{l_t+l_i+l_o}\)To determine the similarities for the tasks ( \(sim_N\) ), incoming and outgoing ( \(sim_{dataflow}\) ) data is aggregated. Afterwards a weighted average is calculated.
Usage #
The usage in ProCAKE is equivalent to the list measure, in fact, the graph measure is a simple extension of the list measure. When using the measures, it is checked at the beginning if they are valid NESTSequentialWorkflows. If this is not the case, no similarity calculation is performed. So the measures only work for NESTWorkflows, which are a subclass of NESTSequentialWorkflow, if they are also valid NESTSequentialWorkflows.
SWA #
For this SWA-based measure, the following parameters can be set.
| Parameter | Type/Range | Default Value | Description |
|---|---|---|---|
| halvingDist | Percentage (Double, [0,1]) | 0.0 | This parameter specifies the distance to the end where the events’ importance shall be one half. |
| constInsertionPenalty | Functional interface | t -> -1.0 | This parameter is used to define a functional interface that gets the specific item being inserted as input. The output must be a negative numeric value. |
| constDeletionPenalty | Functional interface | t -> -1.0 | This parameter is used to define a functional interface that gets the specific item being inserted as input. The output must be a negative numeric value. |
| taskSimName | Similarity Measure (String) | null | The parameter is used to define, which similarity has to be taken for the similarity computation between task nodes. It will be used to calculate local similarities between their semantic descriptions, represented as aggregate objects. The similarity measure, which is referred, must exist in the runtime domain, too. Otherwise, an exception will be thrown. If no taskSimName is defined, a usable data class similarity will be searched. If this one can’t be found, too, an invalid similarity will be returned. |
| dataSimName | Similarity Measure (String) | null | The parameter is used to define, which similarity has to be taken for the similarity computation between data nodes. It will be used to calculate local similarities between their semantic descriptions, represented as aggregate objects. The similarity measure, which is referred, must exist in the runtime domain, too. Otherwise, an exception will be thrown. If no dataSimName is defined, a usable data class similarity will be searched. If this one can’t be found, too, an invalid similarity will be returned. |
| endWithQuery | Flag (boolean) | true | This parameter configures the binding to always end the alignment with the last task of the query can be disabled. |
| ignoreDifferentBeginnings | Enumeration (String) | NONE | This parameter changes the similarity measure so that different beginnings are taken into account in the similarity calculation. It is possible to consider different beginnings in the case (IGNORE_DIFFERENT_BEGINNINGS_CASE), in query and case (IGNORE_DIFFERENT_BEGINNINGS_CASE_AND_QUERY) or to consider no different beginnings at all (NONE). |
| localSimilarities | Flag (boolean) | false | This parameter modifies the returned similarity object of query and case, if this parameter is set to true, the local similarities are added to the similarity object of query and case. |
The SWA-based measure can be instantiated during runtime as follows:
SMGraphSWA smGraphSWA = (SMGraphSWA) simVal.getSimilarityModel().createSimilarityMeasure(
SMGraphSWA.NAME,
ModelFactory.getDefaultModel().getNESTSequentialWorkflowClass()
);
simVal.getSimilarityModel().addSimilarityMeasure(smGraphSWA, "SMGraphSWA");
The similarity measure can be configured using the following parameters:
The halving distance can be specified as a percentage value (denoted as a value from \([0,1]\) ) of the length of the query. The distance is measured starting from the end of the query!
smGraphSWA.setHalvingDistancePercentage(0.5);Insertion and deletion penalty schemes can be specified using a functional interface that gets the specific item being inserted or deleted as input. The output must be a negative numeric value.
smGraphSWA.setInsertionScheme(t -> -0.5); smGraphSWA.setDeletionScheme(t -> -0.5);When the task similarity to use is specified, this overwrites the configuration of the similarity model. It will be used to calculate local similarities between tasks’ semantic descriptions, represented as aggregate objects.
smGraphSWA.setTaskSimilarityToUse("SMStringEquals");When the data similarity to use is specified, this overwrites the configuration of the similarity model. This similarity is then used in the CollectionMapping to calculate local similarities of data nodes (between their semantic descriptions).
smGraphSWA.setDataSimilarityToUse("SMStringEquals");The binding to always end the alignment with the last task of the query can be disabled.
smGraphSWA.setForceAlignmentEndsWithQuery(false);It is possible to calculate the local similarities of query and case, these similarities are added to the similarity object of the query and case calculation.
smGraphSWA.setReturnLocalSimilarities(true);It is possible to consider different beginnings of the similarity calculation. Possible values are:
NONE,IGNORE_DIFFERENT_BEGINNINGS_CASEandIGNORE_DIFFERENT_BEGINNINGS_CASE_AND_QUERY.smGraphSWA.setIgnoreDifferentBeginnings(DIFFERENT_BEGINNINGS_STRATEGIES.IGNORE_DIFFERENT_BEGINNINGS_CASE);
Instantiation via XML is also possible, however, insertion and deletion penalty schemes can only be set to a constant value. Possible values for ignoreDifferentBeginnings are: none, ignore_different_beginnings_case and ignore_different_beginnings_case_and_query.
<GraphSWA name="SMGraphSWA"
class="NESTSequentialWorkflow"
halvingDist="0.5"
taskSimName="SMStringEquals"
dataSimName="SMStringEquals"
constInsertionPenalty="-0.5"
constDeletionPenalty="-0.5"
endWithQuery="false"
ignoreDifferentBeginnings="ignore_different_beginnings_case"
returnLocalSimilarities="true"/>
DTW #
For this DTW-based measure, the following parameters can be set.
| Parameter | Type/Range | Default Value | Description |
|---|---|---|---|
| halvingDist | Percentage (Double, [0,1]) | 0.0 | This parameter specifies the distance to the end where the events’ importance shall be one half. |
| taskSimName | Similarity Measure (String) | null | The parameter is used to define, which similarity has to be taken for the similarity computation between task nodes. It will be used to calculate local similarities between their semantic descriptions, represented as aggregate objects. The similarity measure, which is referred, must exist in the runtime domain, too. Otherwise, an exception will be thrown. If no taskSimName is defined, a data class similarity will be searched. If this one can’t be found, too, an invalid similarity will be returned. |
| dataSimName | Similarity Measure (String) | null | The parameter is used to define, which similarity has to be taken for the similarity computation between data nodes. It will be used to calculate local similarities between their semantic descriptions, represented as aggregate objects. The similarity measure, which is referred, must exist in the runtime domain, too. Otherwise, an exception will be thrown. If no dataSimName is defined, a usable data class similarity will be searched. If this one can’t be found, too, an invalid similarity will be returned. |
| endWithQuery | Flag (boolean) | true | This parameter configures the binding to always end the alignment with the last task of the query can be disabled. |
| ignoreDifferentBeginnings | Enumeration (String) | NONE | This parameter changes the similarity measure so that different beginnings are taken into account in the similarity calculation. It is possible to consider different beginnings in the case (IGNORE_DIFFERENT_BEGINNINGS_CASE), in query and case (IGNORE_DIFFERENT_BEGINNINGS_CASE_AND_QUERY) or to consider no different beginnings at all (NONE). |
| localSimilarities | Flag (boolean) | false | This parameter modifies the returned similarity object of query and case, if this parameter is set to true, the local similarities are added to the similarity object of query and case. |
The DTW-based measure can be instantiated during runtime as follows:
SMGraphDTW smGraphDTW = (SMGraphDTW) simVal.getSimilarityModel().createSimilarityMeasure(
SMGraphDTW.NAME,
ModelFactory.getDefaultModel().getNESTSequentialWorkflowClass()
);
simVal.getSimilarityModel().addSimilarityMeasure(smGraphDTW, "SMGraphDTW");
The similarity measure can be configured using the following parameters:
The halving distance can be specified as a percentage value (denoted as a value from \([0,1]\) ) of the length of the query. The distance is measured starting from the end of the query!
smGraphDTW.setHalvingDistancePercentage(0.5);When using DTW, it could be essential that the scoring matrix is instantiated using negative values for punishing strong dissimilarities. Otherwise, every step in the matrix could increase the overall score. Therefore, a valBelowZero can be introduced that adapts the local similarity scores during calculation in the following way: \(sim_{stretched} = (1 + valBelowZero) \ast sim_{loc} - valBelowZero\) . Thereby, the similarity scores will be mapped from the interval \([0,1]\) onto \([-valBelowZero,1]\) .
smGraphDTW.setValBelowZero(0.5);When the local similarity to use is specified, it overwrites the configuration of the similarity model. It will be used to calculate local similarities between tasks’ semantic descriptions, represented as aggregate objects.
smGraphDTW.setTaskSimilarityToUse("SMStringEquals");When the data similarity to use is specified, it overwrites the configuration of the similarity model. This similarity is then used in the CollectionMapping to calculate local similarities of data nodes (between their semantic descriptions).
smGraphDTW.setDataSimilarityToUse("SMStringEquals");The binding to always end the alignment with the last task of the query can be disabled.
smGraphDTW.setForceAlignmentEndsWithQuery(false);It is possible to calculate the local similarities of query and case, these similarities are added to the similarity object of the query and case calculation.
smGraphDTW.setReturnLocalSimilarities(true);It is possible to consider different beginnings of the similarity calculation. Possible values are:
NONE,IGNORE_DIFFERENT_BEGINNINGS_CASEandIGNORE_DIFFERENT_BEGINNINGS_CASE_AND_QUERY.smGraphDTW.setIgnoreDifferentBeginnings(DIFFERENT_BEGINNINGS_STRATEGIES.IGNORE_DIFFERENT_BEGINNINGS_CASE);
Instantiation via XML can be done as follows. Possible values for ignoreDifferentBeginnings are: none, ignore_different_beginnings_case and ignore_different_beginnings_case_and_query.
<GraphDTW name="SMGraphDTW"
class="NESTSequentialWorkflow"
halvingDist="0.5"
taskSimName="SMStringEquals"
dataSimName="SMStringEquals"
valBelowZero="0.5"
endWithQuery="false"
ignoreDifferentBeginnings="none"
returnLocalSimilarities="true"/>
A* Measures #
Detailed information about the NESTWorkflow representation and the A* algorithm can be found in the paper Similarity Assessment and Efficient Retrieval of Semantic Workflows (Here, referenced as NESTGraph). The latest improvements of the algorithm named A*III are described in the paper A*-Based Similarity Assessment of Semantic Graphs.
Usage of A* similarity measure #
ProCAKE provides a custom A* algorithm specifically designed for all kinds of NESTGraphs.
The A* algorithm maintains a priority queue of open search nodes, i.e., partial solutions with partial mappings between the query graph and the case graph. In each step, the first search node is removed from the queue, is further expanded by adding additional mappings for the next item of the query graph to all possible items of the case graph, and then the newly obtained solutions are added into the priority queue. If such a solution contains a complete mapping of all items in the query graph the A* search terminates. Otherwise, the search continues by expanding the best partial solution in the priority queue.
The order, in which the partial solutions are added to the queue is essential for A*. Therefore, each partial solution is evaluated by a heuristic function. In our case, this function estimates an upper bound for the similarity of a solution, i.e., the maximum possible similarity a mapping of the remaining items of the query graph can achieve. The partial solutions are ranked in the priority queue by their similarity in decreasing order.
The following formula is used for calculating the similarity of a partial solution S: \( f(S) = g(S) + h(S)\) The function g returns the similarity of the already applied mappings and the function h estimates the maximum possible similarity that can be achieved by adding the remaining mappings.
In ProCAKE, there are various implementations of the A* algorithm. The basic search algorithm is the same in all implementations. However, there are differences in the mapping order of items and the underlying heuristic function. These differences will mainly affect performance and resource consumption. If the user does not limit the given resources for the calculation, i.e., the queue size for storing partial mappings, then all three implementations will find the optimal mapping and highest possible similarity value of two given workflow graphs.
Global parameters of all A* implementations #
| Parameter | Type | Default Value | Description |
|---|---|---|---|
| maxQueueSize | Size (int) | -1 | Allows for pruning of the priority queue by restricting the size of the queue. This speeds up the search at the cost of loosing ensured global optimality of the search. By default, the queue size is not limited, which can be set using a negative value. |
| timeout | Time in seconds (int) | -1 | The parameter expects a value given in seconds to abort the similarity computation. If a set timeout is reached, the running computation is terminated immediately and an invalid similarity (-1.0) is returned. By default, timeout is inactive. |
| returnLocalSimilarities | Flag (boolean) | false | The parameter is used to set the complexity of the returned result object. It defines, whether the local similarities of all mappings as well as the local similarities between the semantic descriptions are returned to the similarity object. By default, the option is disabled as this can consume a lot of memory when computing the similarity between complex graphs. |
| returnLocalNodeSimilarities | Flag (boolean) | false | Overwrites the value of returnLocalSimilarities for local similarities of nodes. |
| returnLocalEdgeSimilarities | Flag (boolean) | false | Overwrites the value of returnLocalSimilarities for local similarities of edges. |
| onlyTestForMaxSim | Flag (boolean) | false | Parameter for using A* as binary measure for determining whether the query graph is semantically equal or part of the case graph which always results in an overall similarity of 1.0. This option allows for a more efficient computation since the computation terminates as soon as the estimated similarity of the best-possible solution drops below 1.0. |
The following improvements are enabled by default but can be deactivated by setting the corresponding parameter. However, our evaluation of the A*III implementation indicated that the single improvements as well as the combination allows for speeding up the A* search. Hence, it is recommended to use A*III with all improvements (they are enabled by default).
| Parameter | Type | Default Value | Description |
|---|---|---|---|
| allowPreInitializationOfSolution | Flag (boolean) | true | By enabling the option, the algorithm tries to reduce the search space prior to the search. It detects and adds legal (particularly type-preserving) mappings between query and case nodes to the initial solution for which only one legal mapping exists. Regarding the graph representation, it is advisable to assign different types to graph elements whenever their semantic descriptions are disjoint to increase the chance that only one legal mapping between nodes exists. |
| allowCaseOrientedMapping | Flag (boolean) | true | By enabling the option, the mapping orientation becomes adaptive. If the query graph is larger than the case graph, we assume that the mapping process can be made more efficient by orienting the mapping towards the case elements. This is referred to as case-oriented mapping. Please note that the direction of the mappings and the similarity assessment is unaffected, i.e., mapping and similarity are still oriented from the query elements to the case elements. |
Global parameters for custom weighting of graph items #
| Parameter | Type | Default Value | Description |
|---|---|---|---|
| defaultWeight | Weight (Double, [0, positive finite value]) | 1.0 | The default weight for attributes that is used if no specific graph item weight is defined. |
Clearing the weights from the initial graph item classes ensures a clean slate for setting custom weights. If no specific weight is assigned to a graph item class, a default weight is used instead. Custom weight values can be defined as whole number, allowing to assign different levels of importance to graph items. The weights are normalized before the similarity is determined. The final similarity value falls within interval [0, 1].
At build-time, the measure can be configured as follows in XML:
<GraphAStarThree name="SMGraphAStarWeighted" class="NESTWorkflow" defaultWeight="0.0">
<ClassWeight class="NESTTaskNode" weight="1"/>
<ClassWeight class="NESTControlflowEdge" weight="2"/>
</GraphAStarThree>
To create this measure during runtime, the following code has to be used:
SimilarityModel simModel = SimilarityModelFactory.getDefaultSimilarityModel();
SMGraphAStarThree aStarWeight = (SMGraphAStarThree) simModel.createAndRegisterSimilarityMeasure("SMGraphAStarWeighted",
SMGraphAStarThree.NAME,
ModelFactory.getDefaultModel().getNESTWorkflowClass());
aStarWeight.clearWeights();
aStarWeight.setDefaultWeight(0.0);
aStarWeight.setWeight(NESTTaskNodeClass.CLASS_NAME, 1.0);
aStarWeight.setWeight(NESTControlflowEdgeClass.CLASS_NAME, 2.0);
A* Implementations #
The A* implementations use the following strategies, to estimate the similarity and select the next nodes and edges:
A*I #
This version uses a naive estimation function, which assesses the similarity of each not yet mapped node or edge as \(1.0\) .
To calculate the contribution of each not mapped element to the overall similarity, the following formula is used:
\(h_{ I }(S) = \frac{\left\lvert S.N \right\rvert + \left\lvert S.E \right\rvert }{ \left\lvert N _{ q } \right\rvert + \left\lvert E _{ q } \right\rvert }\)Here, S.N stands for the nodes and S.E for the edges, which haven’t been mapped yet.
First all nodes are matched, before the edges are selected. The selection of the elements in the node set and edge set respectively is random.
The measure can be used as follows:
<GraphAStarOne name="SMGraphAStarOne" class="NESTWorkflow"/>
To create this measure during runtime, the following code has to be used:
SMGraphAStarOne smGraphAStarOne = (SMGraphAStarOne) simVal.getSimilarityModel().createSimilarityMeasure(
SMGraphAStarOne.NAME,
ModelFactory.getDefaultModel().getNESTWorkflowClass()
);
simVal.getSimilarityModel().addSimilarityMeasure(smGraphAStarOne, "SMGraphAStarOne");
A*II #
This version uses a better informed admissible heuristic. For each not mapped node or edge the best possible similarity is calculated, which happens independently of the mapping of the other nodes and edges. These values can be computed prior to search and cached.
To calculate the contribution of each not mapped element to the overall similarity, the following formula is used:
\(h_{ II }(S) = \sum_{x \in S.N \cup S.E }{ }{ \left( \max\limits_{{y \in N_{ c } \cup E_{ c }}} \left\{ sim_{ E/N } \left( x,y \right) \right\} \right)} * \frac{ 1 }{ \left\lvert N_{ q } \right\rvert + \left\lvert E_{ q } \right\rvert }\)Here, N stands for all nodes and E for all edges. The variables q and c stand for query and case. As before S.N stands for the nodes and S.E for the edges, which are not mapped yet.
Edges are matched as soon as possible. Because edges can only be matched, if the connected nodes are matched, the branching factor is low.
This implementation selects the nodes, as long as there are no legal edges, which can be selected.
The measure can be used as follows:
<GraphAStarTwo name="SMGraphAStarTwo" class="NESTWorkflow"/>
To create this measure during runtime, the following code has to be used:
SMGraphAStarTwo smGraphAStarTwo = (SMGraphAStarTwo) simVal.getSimilarityModel().createSimilarityMeasure(
SMGraphAStarTwo.NAME,
ModelFactory.getDefaultModel().getNESTWorkflowClass()
);
simVal.getSimilarityModel().addSimilarityMeasure(smGraphAStarTwo, "SMGraphAStarTwo");
A*III #
This implementation builds up on the implementation of A*II but uses a more informed heuristic and provides additional improvements, which are briefly explained in the following. Please refer to the paper A*-Based Similarity Assessment of Semantic Graphs for a more detailed description and an experimental evaluation.
MoreInformedHeuristic: A well-informed admissible heuristic \(h(S)\)
is crucial for the efficiency of the A* search. This algorithm uses a more informed heuristic. In contrast to heuristic \(h_{II}(S)\)
, the novel heuristic \(h_{III}(S)\)
considers the current mapping between query and case nodes and edges for determining the maximum possible similarity a new mapping can achieve. It excludes mappings from the estimation that do not lead to a legal mapping when added to the current mapping. Hence, this heuristic is computationally more expensive since all independent mappings must be computed in advance and the heuristic must be updated with respect to the current mapping. However, since the heuristic is more accurate, we expect that partial solutions with non-optimal (but legal) mappings are ranked lower in the priority queue and hence the overall performance of the search is improved.
The following improvement can be deactivated by setting the corresponding parameter. However, our evaluation indicated that the single improvement as well as the combination with the other improvements allows for speeding up the A* search. Hence, it is recommended to use A*III with all improvements (they are enabled by default).
| Parameter | Type | Default Value | Description |
|---|---|---|---|
| useHeuristicBasedItemSelection | Flag (boolean) | true | By enabling this option, the estimated similarities from the heuristic are used to select the next graph element to be mapped. Besides the heuristic, the selection of the next element to be mapped is essential for the A* search and has a significant impact on the performance. If the next element is mapped with a high similarity, the expanded solution is ranked in front of the priority queue. The new select function first selects the element whose best-possible mappings are rated with the highest similarity. If several of such elements exist, the element is chosen with the smallest number of best-possible mappings. If still several elements remain, the element is chosen randomly according to an internal ID analogous to A*II. |
If pruning of the solution space shall be used due to limited computing resources, the queue size can be set to value larger zero (negative values disable pruning). Please note that the queue size should be set much smaller than for A*II. The algorithm even produced reasonable results using only a queue size of one.
Sample configurations #
At build-time, the measure can be configured as follows in XML:
<GraphAStarThree name="SMGraphAStarThree"
class="NESTWorkflow"
maxQueueSize="10"
timeout="-1"
returnLocalSimilarities="false"
onlyTestForMaxSim="false"
allowCaseOrientedMapping="true"
allowPreInitializationOfSolution="true"
useHeuristicBasedItemSelection="true"/>
At run-time, the measure can be created as follows:
SMGraphAStarThree smGraphAStarThree = (SMGraphAStarThree) SimilarityModelFactory.getDefaultSimilarityModel().createSimilarityMeasure(
SMGraphAStarThree.NAME,
ModelFactory.getDefaultModel().getNESTWorkflowClass()
);
smGraphAStarThree.setMaxQueueSize(10);
smGraphAStarThree.setTimeout(-1);
smGraphAStarThree.setReturnLocalSimilarities(false);
smGraphAStarThree.setOnlyTestForMaxSim(false);
smGraphAStarThree.setAllowCaseOrientedMapping(true);
smGraphAStarThree.setAllowPreInitializationOfSolution(true);
smGraphAStarThree.setUseHeuristicBasedItemSelection(true);
simVal.getSimilarityModel().addSimilarityMeasure(smGraphAStarThree, "SMGraphAStarThree");
Similarity between two graphs #
Since NESTWorkflows are a complex data structure, we have to define how a similarity value between two workflows graphs can be calculated. The basic idea of the similarity calculation is to map NESTGraphItemObjects from the query graph to NESTGraphItemObjects from the case graph. To show what this mean we will look at an example.
Example #
In our example, we have two workflow graphs which coincidentally have the same layout, meaning that both NESTWorkflows consist of 1 WorkflowNode, 2 TaskNodes, 1 DataNode, 3 PartOfEdges, 2 DataflowEdges and 1 ControlflowEdge.
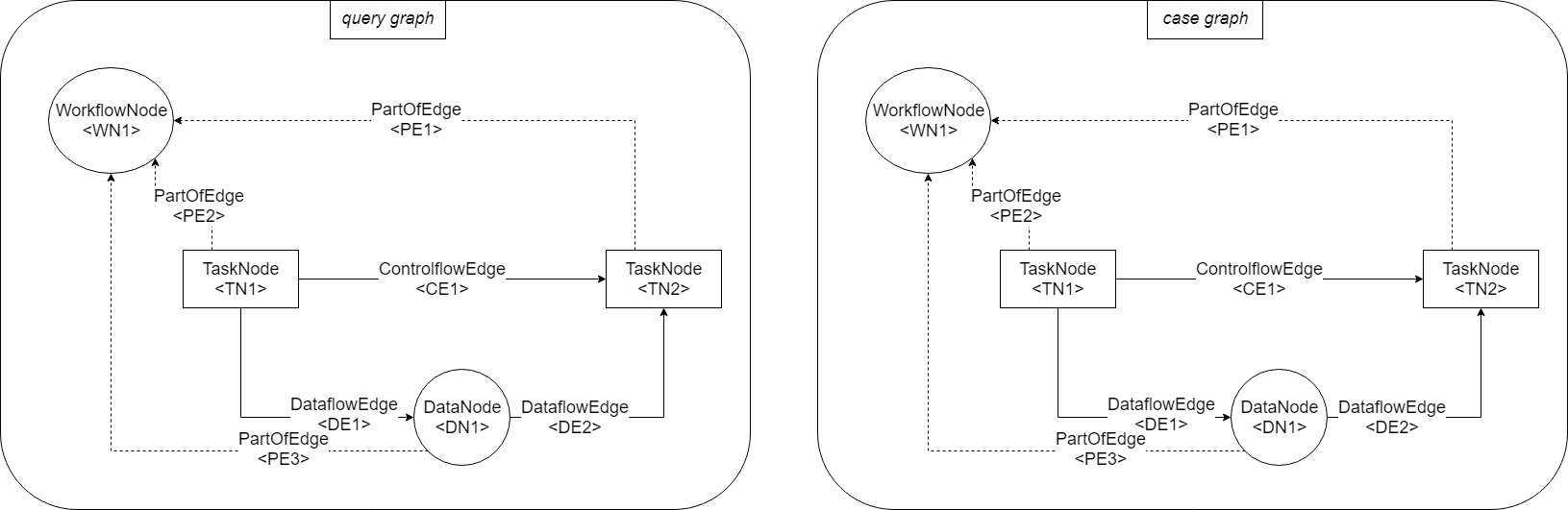
Like already said before, our algorithm will try to find mappings between items from the query graph and items from the case graph. Before we continue with the example, we will first have to take a look at what exactly a mapping actually is.
Mappings #
In our A*-algorithm, we use the phrases legal mapping and illegal mapping to determine whether such a mapping is allowed or not. Our algorithm will only create and work on legal mappings.
Rules for legal mappings:
A node can only be mapped to another node; mapped nodes must be of the same type:
- Mapping: \(\{(\text{TN1}, \text{TN2})\}\)
is a legal mapping because TN1 and TN2 are nodes and are of type
TaskNode.
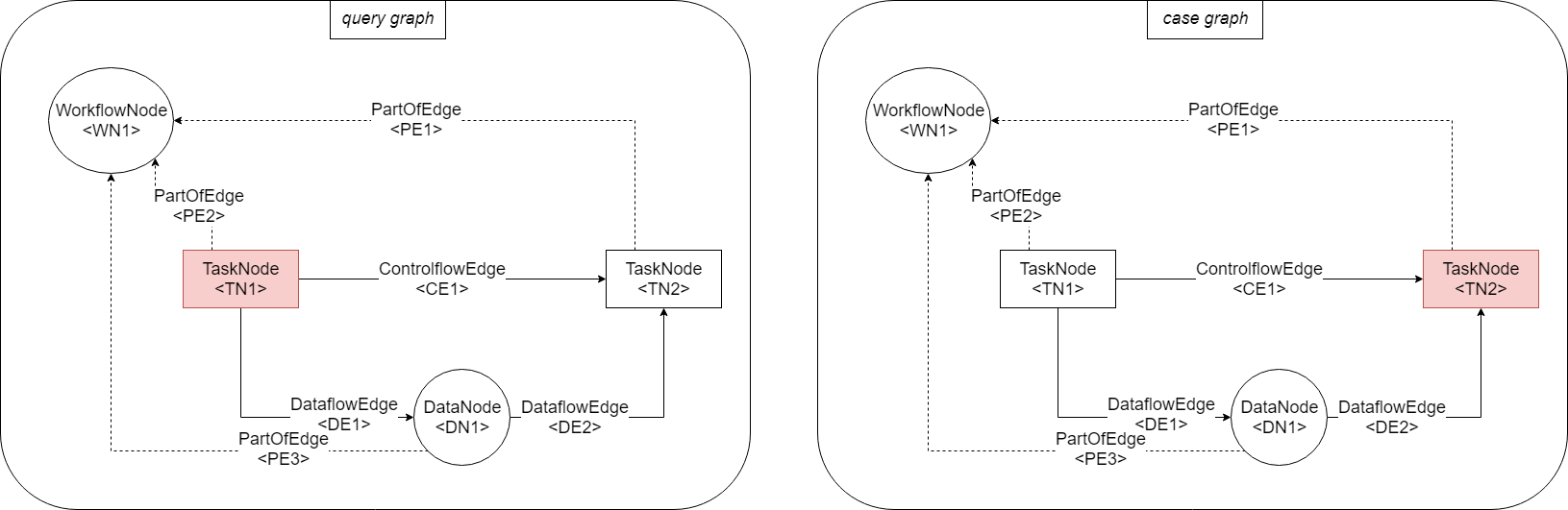
- Mapping: \(\{(\text{TN2}, \text{DN1})\}\)
is not a legal mapping because TN2 and DN1 are not of the same type. TN2 is a
TaskNodebut DN1 is aDataNode.
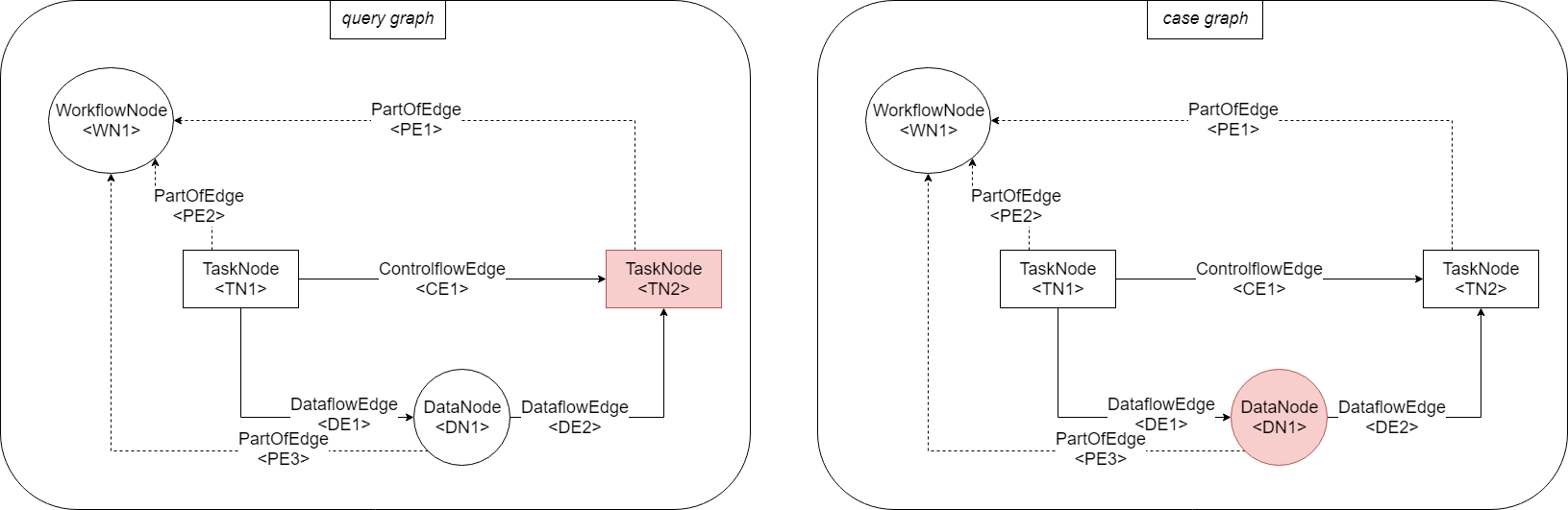
- Mapping: \(\{(\text{TN2}, \text{TN1}), (\text{DN1}, \text{DN1})\}\) is a legal mapping. TN2 is mapped to TN1. And DN1 is mapped to DN2. Both pairs in this mapping are allowed making the overall mapping legal.
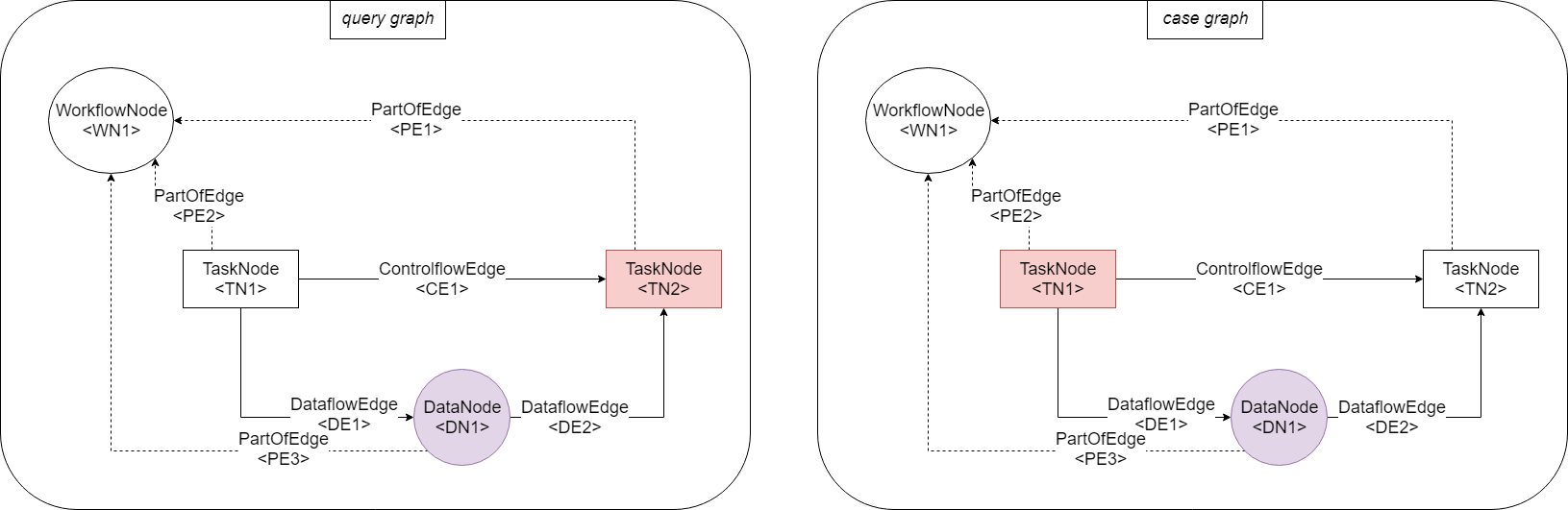
- Mapping: \(\{(\text{TN2}, \text{TN1}), (\text{TN1}, \text{DN1})\}\) is not a legal mapping. The pair TN2, TN1 is allowed. However, TN1 is not allowed to be mapped to DN1. This makes the whole mapping illegal.
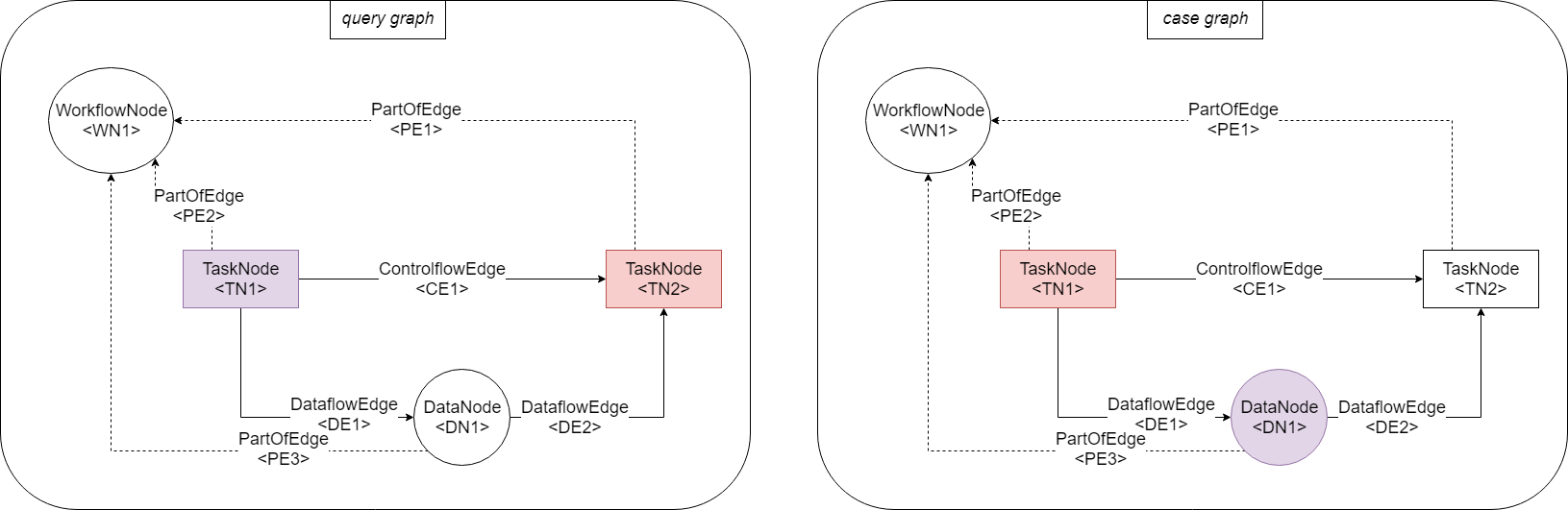
- Mapping: \(\{(\text{TN1}, \text{PE1})\}\) is not a legal mapping. TN1 is a node, but PE1 is an edge. Nodes must not be matched with edges.
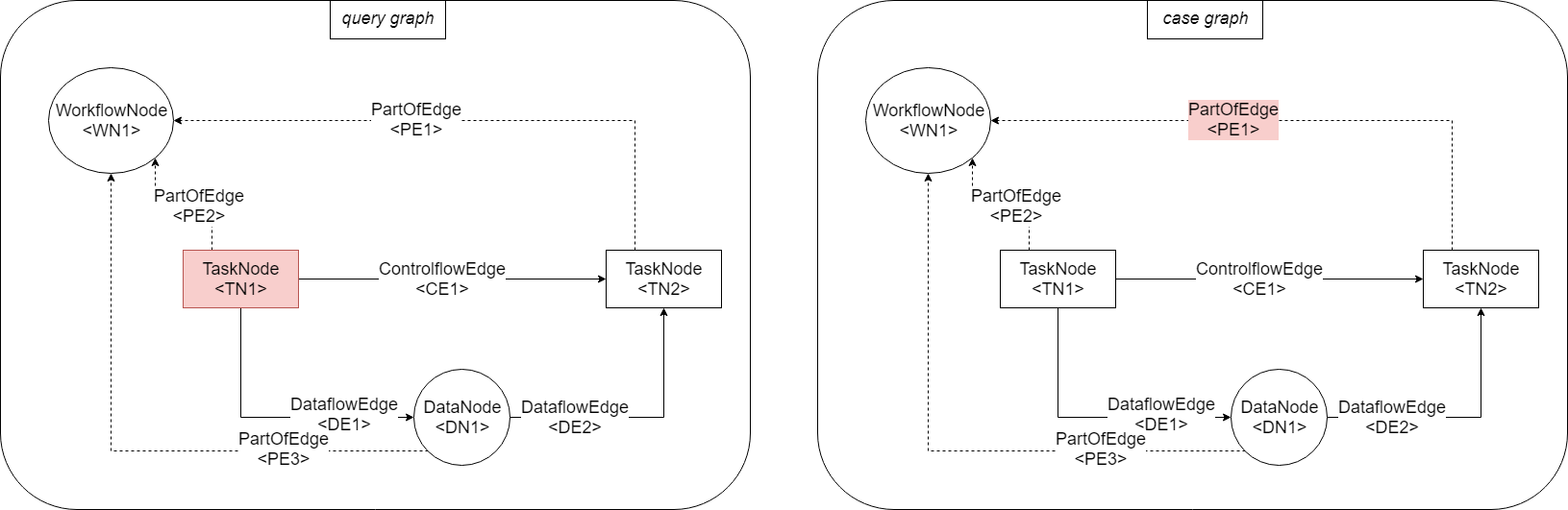
An edge can only be mapped to an edge; mapped edges must be of the same type; edges can only be mapped, if the endpoints of those two edges have already been mapped (the predecessor of edge A has to be mapped to predecessor of edge B and successor of edge A has to be mapped to successor of edge B):
- Mapping: \(\{(\text{CE1}, \text{CE1})\}\) is not a legal mapping. CE1 cannot be mapped to CE1, because the endpoints are not mapped.
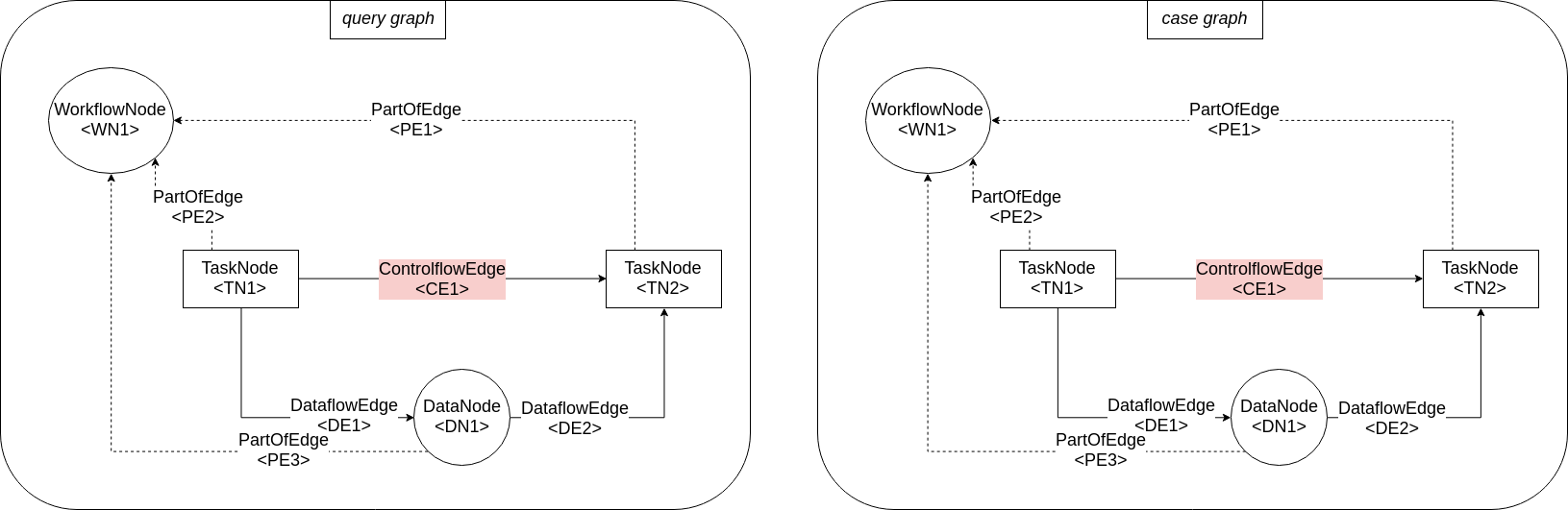
- Mapping: \(\{(\text{CE1}, \text{CE1}), (\text{TE1}, \text{TE2}), (\text{TE2}, \text{TE1})\}\) is not a legal mapping. CE1 cannot be mapped to CE1, because the endpoints are not mapped correctly.
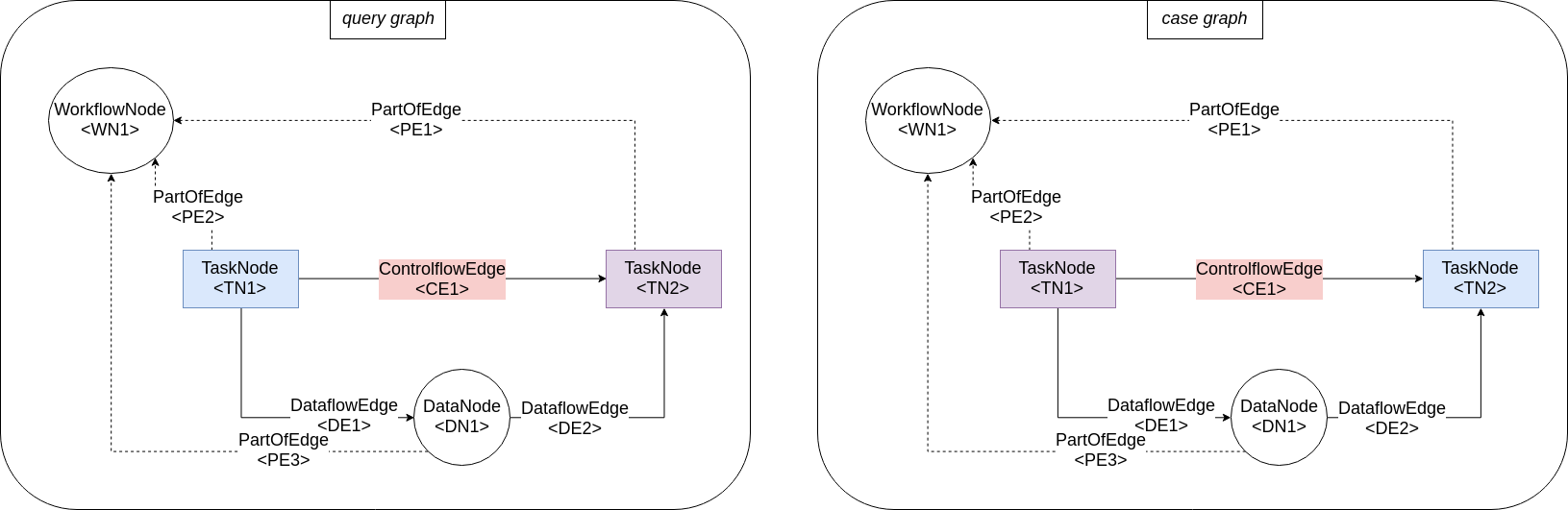
- Mapping: \(\{(\text{CE1}, \text{CE1}), (\text{TE1}, \text{TE1}), (\text{TE2}, \text{TE2})\}\) is a legal mapping. This is the only way to be able to map CE1 to CE1. This mapping is valid, because the predecessor T1 of C1 is mapped to the predecessor T1 of C1 and because the successor T2 of C1 is mapped to the successor T2 of CE1.
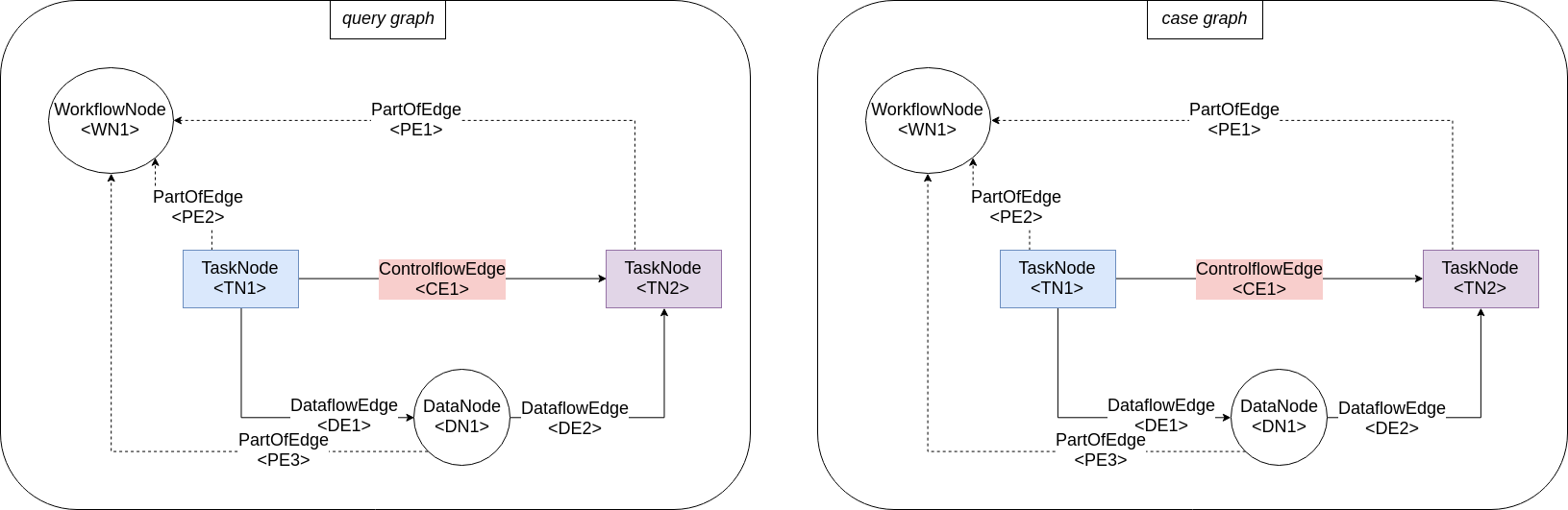
Application Example #
In the following, a simple example of two NEST workflow graphs is shown:
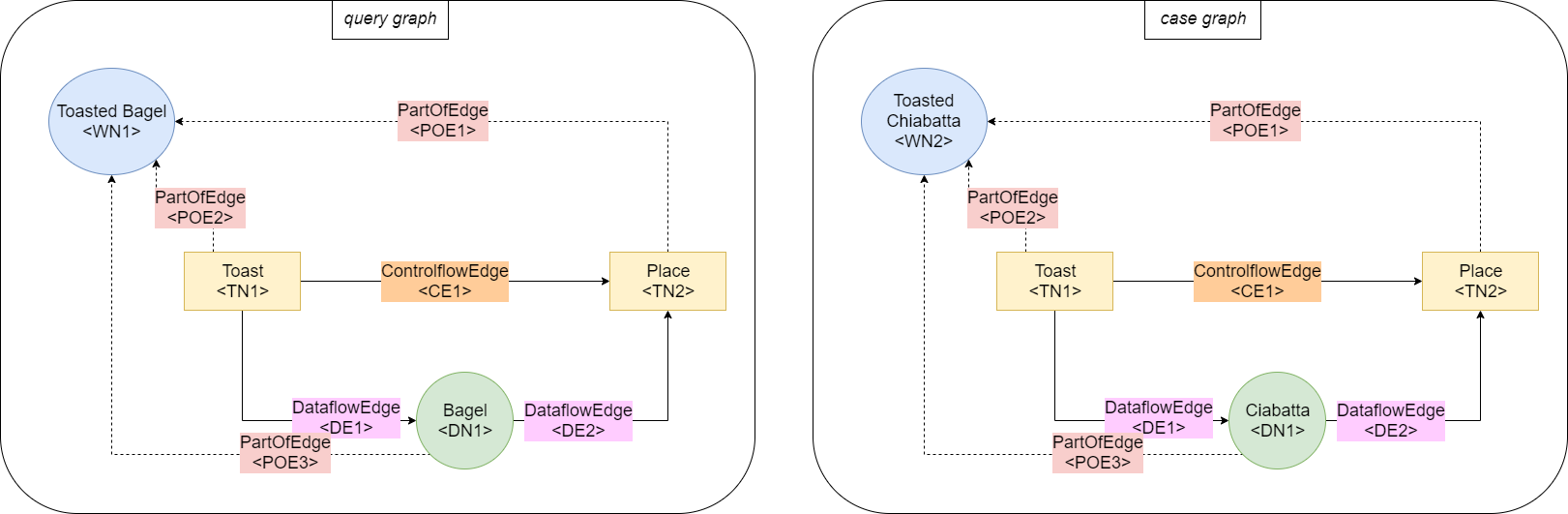
The query graph describes a very simple recipe for a toasted bagel, the case graph describes a very simple recipe for a toasted ciabatta. Because the recipes have many similar task steps and similar ingredients, it can be assumed that the two graphs have a high value for their similarity to one another.
The sets \( N_{ q } \) and \( E_{ q } \) have the following elements:
\(N_{ q } = \left\{ WN1_{q}, TN1_{ q }, TN2_{ q }, DN1_{ q } \right\} \\ \\ E_{ q } = \left\{ POE1_{ q }, POE2_{ q }, POE3_{ q }, DE1_{ q }, DE2_{ q }, CE1_{ q } \right\}\) Here, WN stands for Workflow Node, TN for Task Node, DN for Data Node, POE for Part of Edge, DE for Dataflow Edge and CE for Controlflow Edge.
First, the sets of search nodes \( S.N \) and \( S.E \) are filled with nodes and edges of the query, that are not mapped yet:
\(S.N = \left\{WN1_{q}, TN1_{ q }, TN2_{ q }, DN1_{ q }\right\} \\ S.E = \left\{ POE1_{ q }, POE2_{ q }, POE3_{ q }, DE1_{ q }, DE2_{ q }, CE1_{ q }\right\}\)In the following, the similarity computation between these two graphs is described by using the different A* implementations.